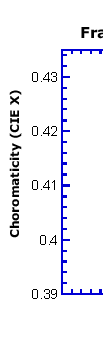| How do we make clinical judgments about ocular appearance?
This is a critical question as it relates to diagnosis (and prognosis)
in eye care since so much diagnostic skill is based on recognising
the unique macro and micro appearance of many diseases/conditions
affecting the eye. In addition to diagnosis, though, appearance
judgment is vital in assessing the changes to the eye that occur
with treatment to determine if an intervention is effective. The
latter can be particularly problematic because in deciding on
differences we are automatically assigning numbers to the appearance
we are judging even if those are simple binary decisions worse/not
worse or worse/better.
| |
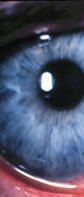
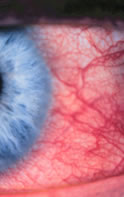
| Figure 1: The problem
can be stated in relationship to this image: How red is this
eye and is it getting better or worse? |
These types of judgement are not solely to diagnose and track
clinical changes; the words and numbers used are clinical summaries
that specify some useful attribute about the patient. If the words
or numbers faithfully represent the underlying condition described,
these words or numbers are measurements and the numbers form the
basis of a scale. Utilising this scale is clinical grading with
the standard being the CCLRU
grading scales.
Clinical grading of the anterior segment is something of a mystery.
Although there has been some scientific study of it, we know almost
nothing about how the skills are acquired and how clinicians actually
make the grading judgments. All of the experiments have been about
how the scales themselves are used or how to automate the process
and very few have been about scale design and verification. So
although we are starting to understand how clinicians use the
various scales that are available, we do not know whether the
scales actually measure the attribute they are designed to measure!
There are a number of things we do know about anterior segment
scaling. In their simplest forms we are very good at the basic
judgments required. Humans can discriminate colour, form, depth
and texture very well, so the basic building blocks of judging
appearance are present. If we complicate the task by making all
of these basic visual judgements on eyes (or sometimes as is done
experimentally, on images of eyes), we know that we can reliably
perform the grading. Although there are slight differences, it
generally doesn’t matter much what kind of scale is used;
one with just reference words is more or less the same as one
with reference pictures, one based on many pictures (or even a
movie of the condition of an eye worsening) is used with surprisingly
similar results to the other 2.For example, the next time a red
eye is seen it will generally be judged to be red. This suggests
that clinicians have rules about using scales that they use similarly
from one time to the next. There are big problems though with
repeatability between observers; a red eye judged by someone may
be judged to be not so red by another. What this implies is that
even though clinicians have access to the same scales (for example
a set of photographic reference pictures that define a range of
a condition), the rules each clinician chooses to use when applying
the scale differs. There are suggestions that perhaps training
may affect this, but there are also results showing that it is
unaffected by training! Finally there is one more thing about
how we grade; we like to use “pretty” numbers that divide
the scale into predictable amounts. This results in grades that
cluster in particular positions on the scale.
So what can we do? There have been a number of demonstrations
of the feasibility of automating the clinical grading of bulbar
redness. This allows us the luxury of objectively extracting the
salient data from the eye being assessed. This is illustrated
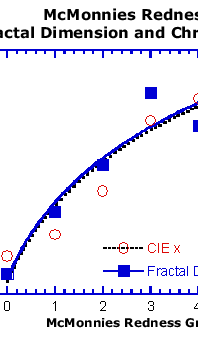
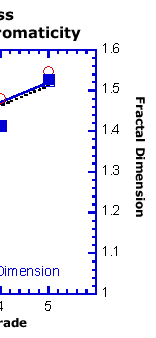
using the McMonnies redness scale showing that two objective measures
of the images that form the basis of the scale behave in remarkably
similar ways and reflect the scale quite well. One (fractal dimension)
captures details of the blood vessels in the images and the other
(chromaticity component CIE x) captures the overall redness in
the image. The same logic and similar techniques should work with
other types of ocular redness, corneal and conjunctival staining
and perhaps even with something as complicated as tarsal roughness.
With the availability of high speed desktop computers, this is
almost a reality. The major difficulty is still that all the algorithms
described need some sort of operator to define areas to be measured
and the exact details of the measurement. Perhaps eventually,
though we will have computerised techniques developed that will
allow us to completely objectively quantify ocular appearance.
What can we do in the mean time? Individually, our grading is
repeatable, so we should continue to use the scales in ways similar
to what we are doing now. What we are not that good at is being
consistent with our colleagues. If we are working in settings
where patients are being seen by multiple practitioners, it is
critical that the same scales be used and the rules applied, to
ensure that assigned numbers to appearance by different clinicians
are the same. Finally, we should think about establishing clinical
standards that would promote the international use of the same
scales, using the same rules for each scale. This is not trivial
and entails developing standards committees, methods to design
and verify scales and eventually the international promotion of
these scales in the professions who would benefit from their use.

| |
| Figure 2: McMonnies
Redness Fractal Dimension and Chromaticity. |
|



 Trefford
Simpson, Dip. Optom., M.Sc., Ph.D.
Trefford
Simpson, Dip. Optom., M.Sc., Ph.D.